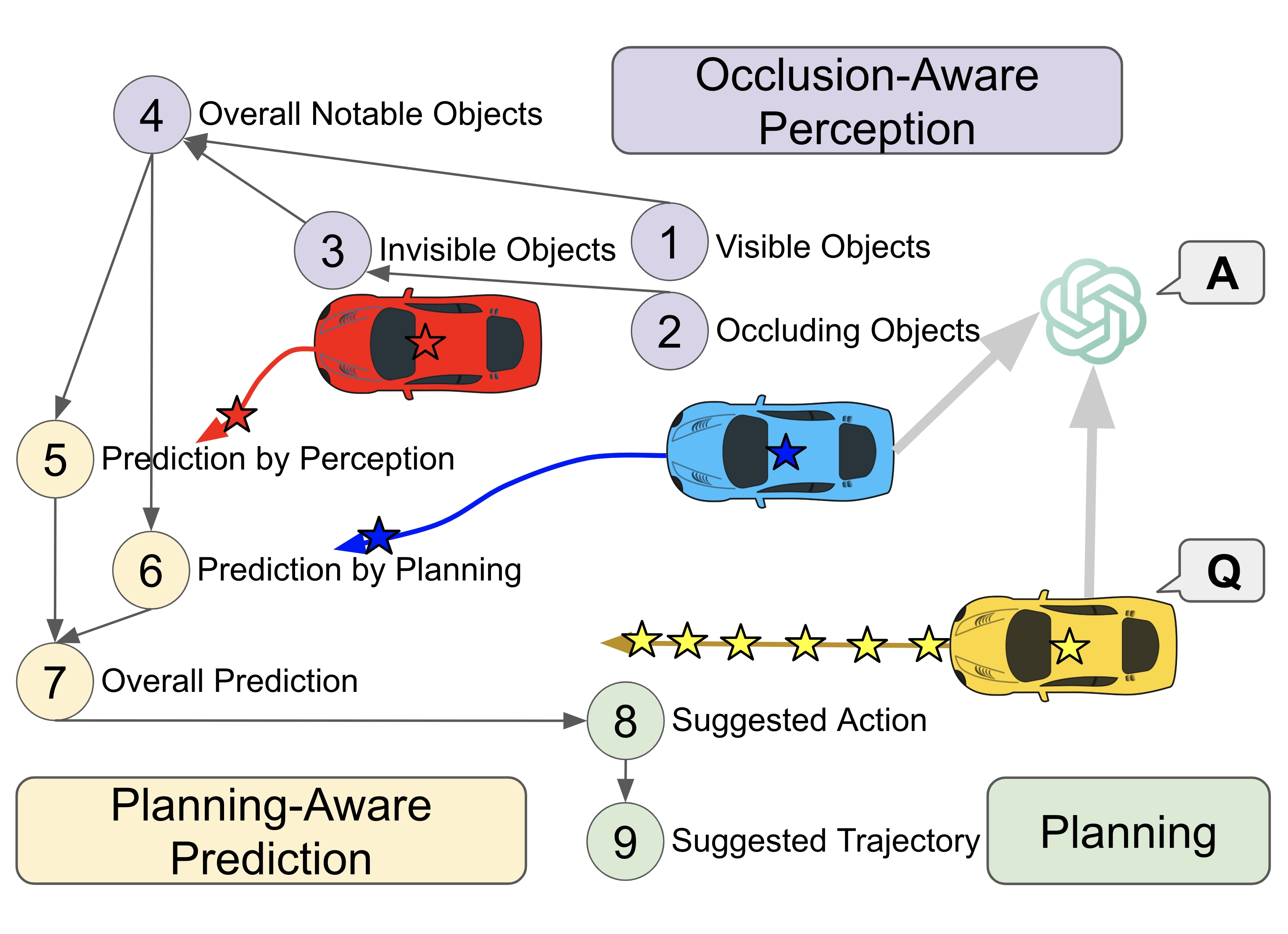
We propose the first graph-of-thoughts framework specifically designed for MLLM-based cooperative autonomous driving. Our graph-of-thoughts includes our proposed novel ideas of occlusion-aware perception and planning-aware prediction. We curate the V2V-GoT-QA dataset and develop the V2V-GoT model for training and testing the cooperative driving graph-of-thoughts. Our experimental results show that our method outperforms other baselines in cooperative perception, prediction, and planning tasks. For more details, please refer to our paper at arxiv.
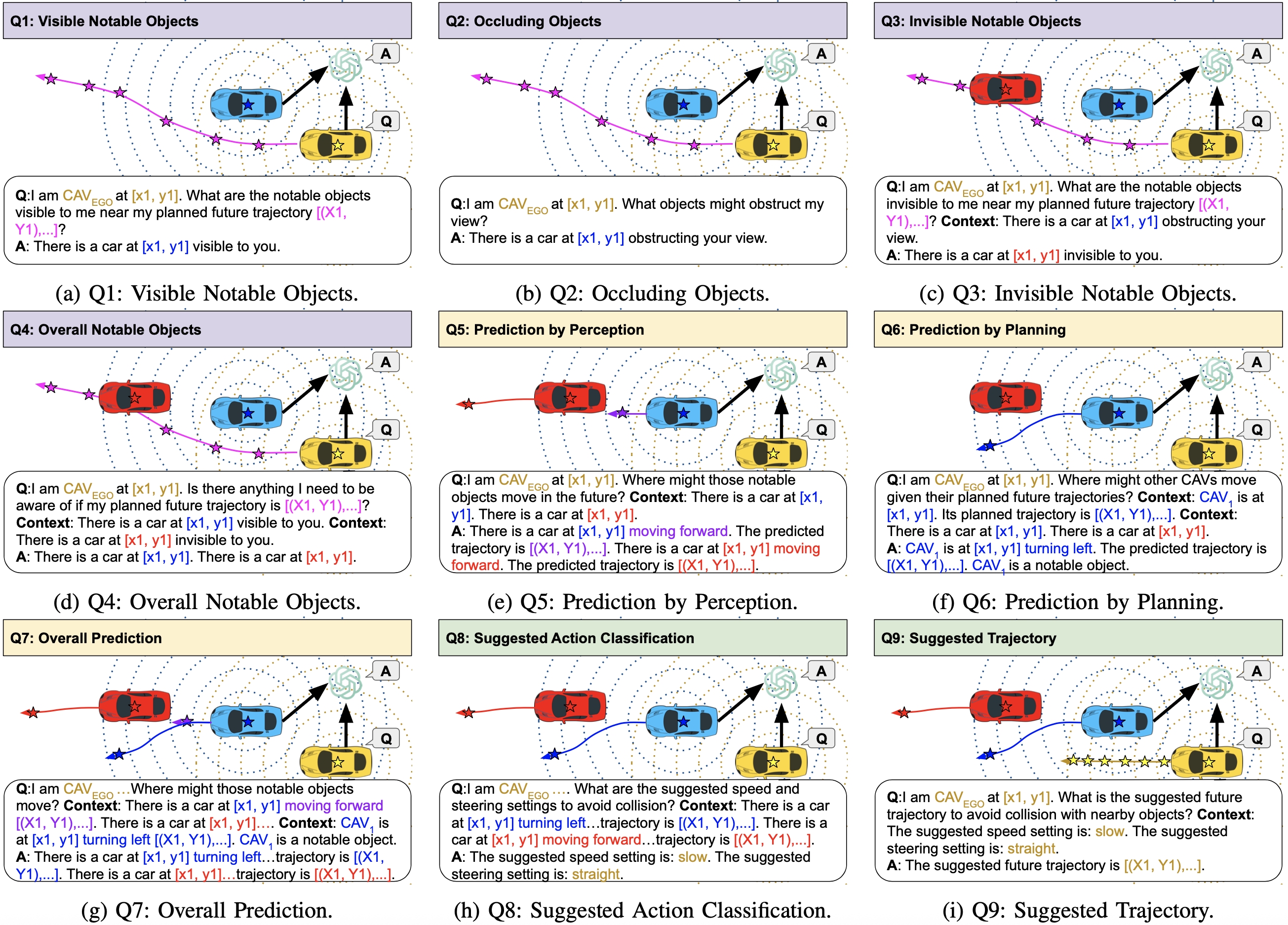
Our V2V-GoT-QA dataset includes 9 types of perception, prediction, and planning QA samples. Our proposed occlusion-aware perception questions (Q1 - Q4) consider visible, occluding, and invisible objects. Our proposed planning-aware prediction questions (Q5 - Q7) include prediction by perception features and prediction by other CAVs' current planned future trajectories. Our planning questions (Q8 - Q9) provide the suggested action settings and waypoints of future trajectories to avoid potential collisions, as illustrated in the following figures.
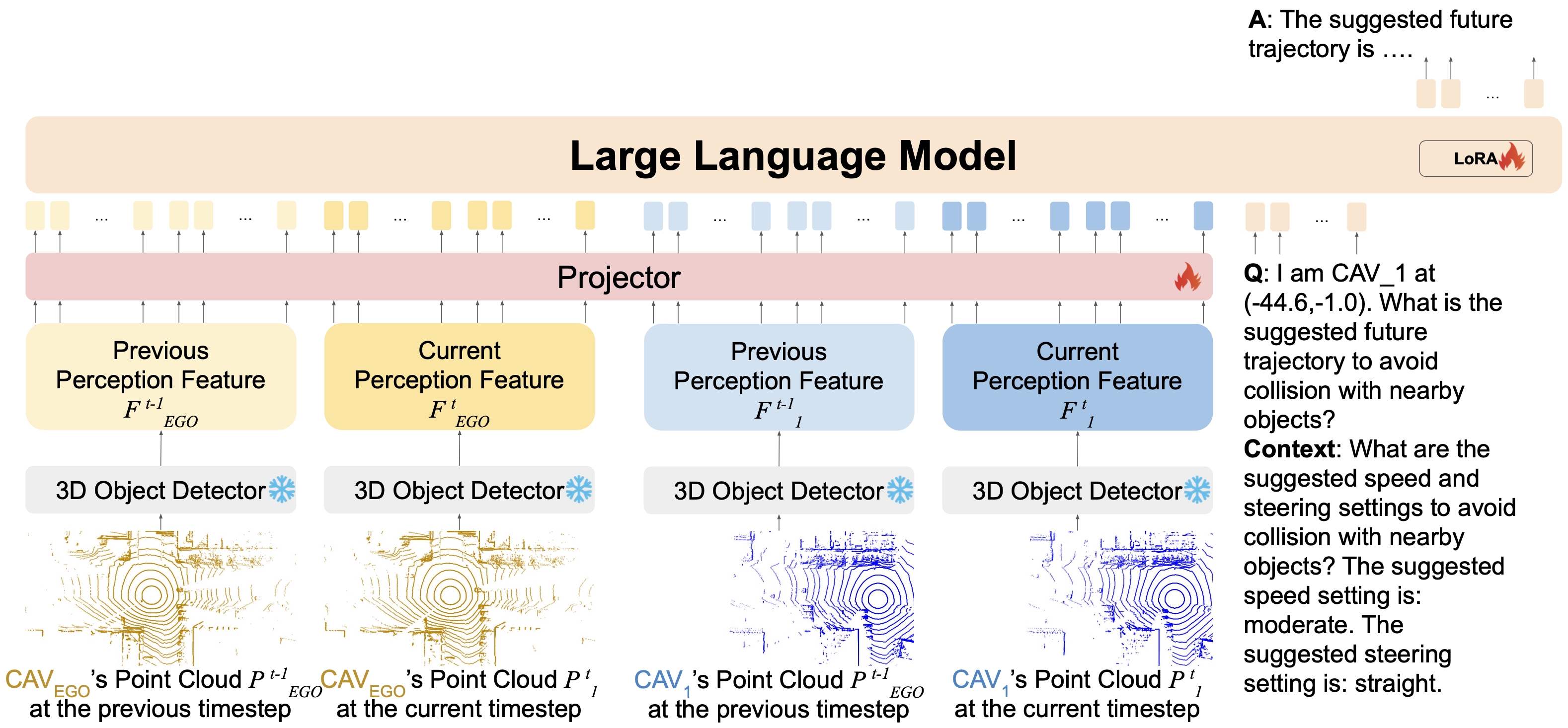
Our V2V-GoT uses the perception features at the current and previous timesteps from all CAVs as the input of the project layers in the MLLM to generate the visual tokens. The MLLM takes the visual tokens and the language tokens from the question and the context as input and generates the final answer in the natural language format.
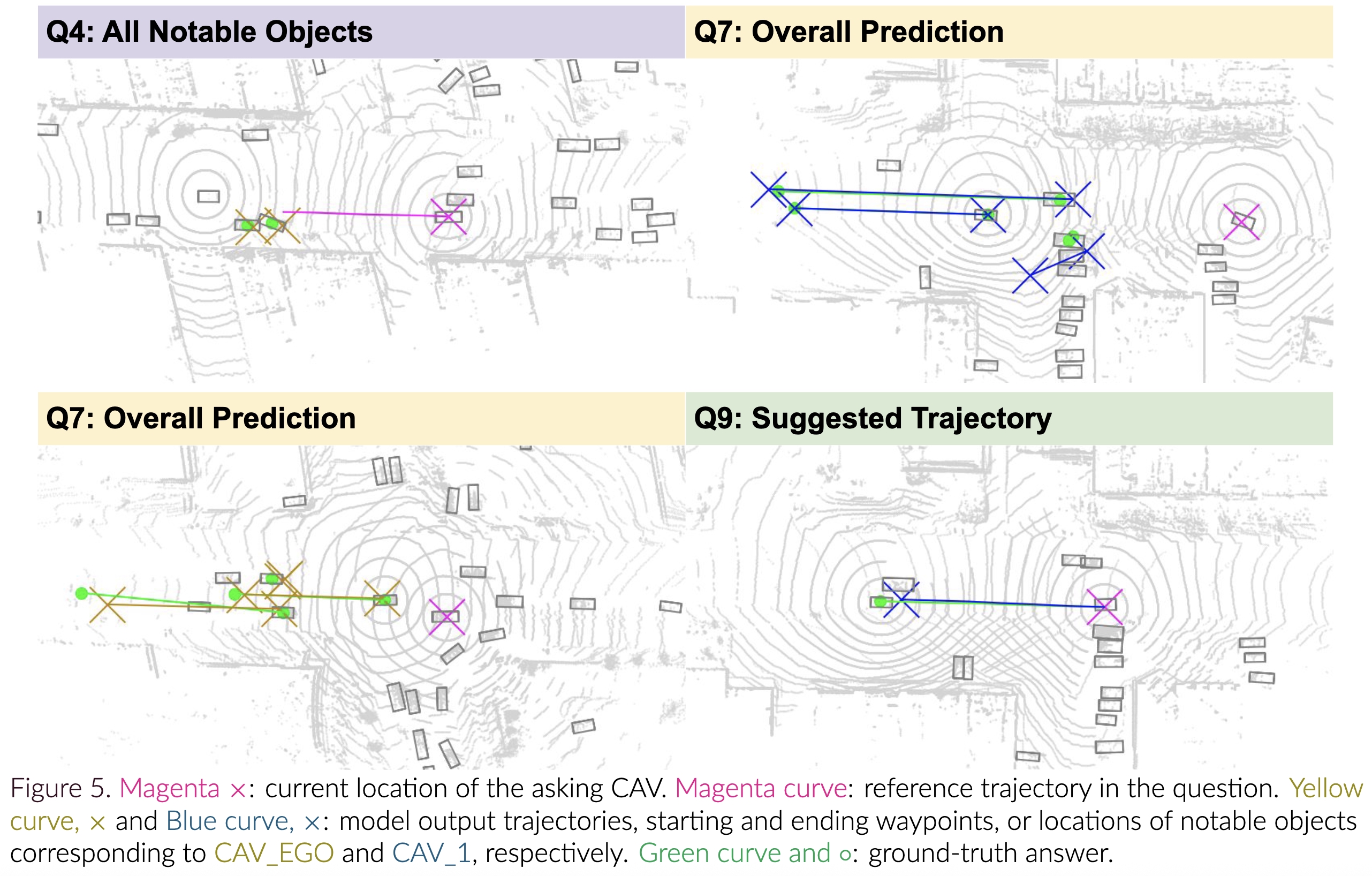
The following figures show the V2V-GoT's qualitative results on V2V-GoT-QA's testing split. For more details, please to refer to our paper at arxiv.